Stable Diffusion Web UI Brings Generative AI Closer to the General Public
Generative AI is a popular and trending topic, particularly in the realm of image generation. DALL·E 2 and MidJourney are widely known as the go-to applications or models for general users. However, you may be wondering about the significance of Stable Diffusion web UI. Well, let’s dive in and find out!
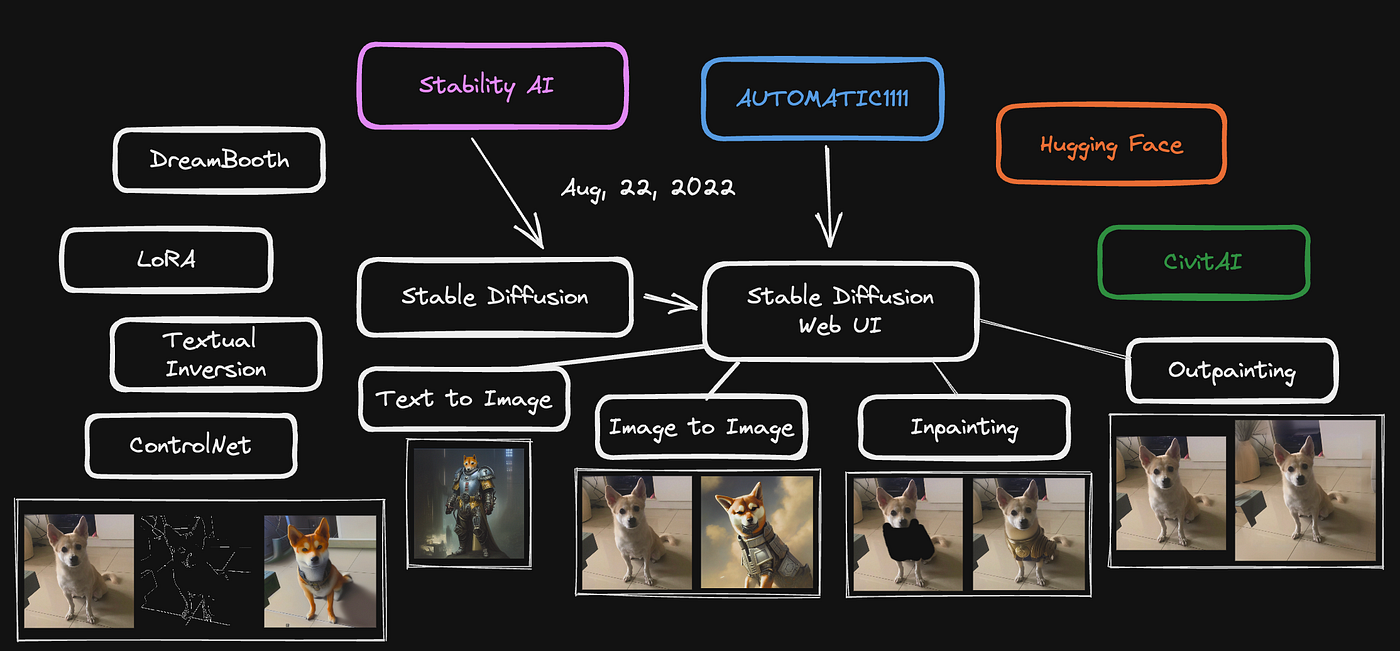
What is Stable Diffusion?

In 2022, Stability AI, in collaboration with academic researchers and non-profit organizations, released Stable Diffusion, a deep learning model known for its text-to-image capabilities. The model is primarily utilized to generate intricate images based on text descriptions. However, it can also be employed for tasks like inpainting, outpainting, and generating image-to-image translations using text prompts.
Unlike DALL·E 2 and MidJourney, the model weights and scripts are accessible to everyone. As a result, everyone has the opportunity to fine-tune the model or build upon it to suit their specific use cases.You can simply try it on the Hugging Face Space ⬇️
License
While the model is open-sourced, there are still policies that need to be adhered to.
The released model comes with a permissive license, called Creative ML OpenRAIL-M, which permits both commercial and non-commercial usage. The license emphasizes the ethical and legal use of the model and requires it to be distributed with accompanying documentation. Furthermore, end users of the model must have access to this license in any service that employs it.
Stable Diffusion Web UI
In 2022, AUTOMATIC1111 created the repository called “stable-diffusion-webui,” which essentially enables the manipulation of Stable Diffusion using a web user interface (UI). Although the UI may not be user-friendly for the general public, it is a significant improvement compared to running the model through the terminal. I would argue that it is now completely accessible to non-developers. As time has passed, you can now have a great deal of fun using it.
Text to Image Generation
Text to Image Generation is a fundamental use case that is often associated with stock photo services, but its capabilities go beyond that. It possesses remarkable power, enabling anyone to generate conceptual images based on their descriptions(prompts).

Image to Image Generation
Image to Image Generation incorporates prompts while taking the input image into consideration. Through img2img, you gain the ability to regulate the generation process using visual input, rather than solely relying on prompts.

Image Inpainting
Inpainting can be regarded as a novel form of AI-based Photoshop (AI PS). It enables you to guide the model to draw within specific regions using your prompts. By providing appropriate prompts and masks, it can seamlessly generate realistic photos.
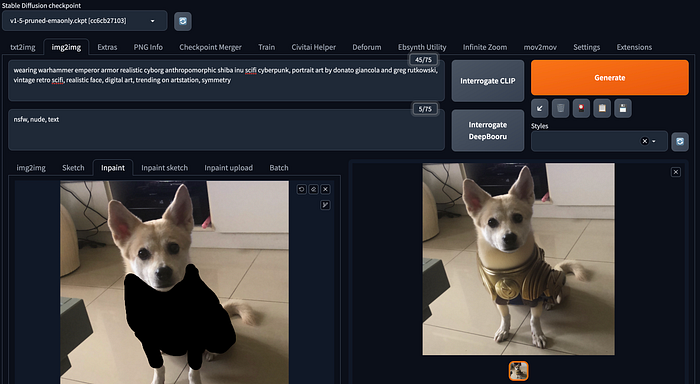
Image Outpainting
Similar to Image Inpainting, Outpainting allows the model to expand the image by utilizing both the existing visual context and prompts.
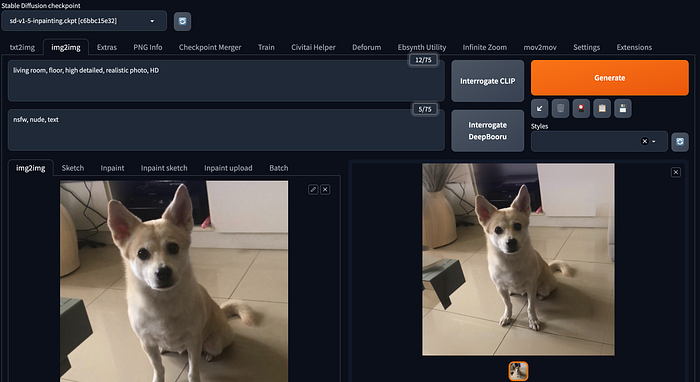
Image to Image Generation with ControlNet
ControlNet in Image to Image Generation allows for the incorporation of low-level details, such as changing color and texture, while preserving the high-level features of the image. In addition to providing a mask to guide the model, the utilization of ControlNet enhances the generation process.

In this section, we have only discussed the fundamental use cases of “Stable Diffusion Web UI”. Nevertheless, the repository has garnered contributions from over four hundred individuals. Thanks to the developer community, numerous extensions can be installed on “Stable Diffusion Web UI”. One notable extension is Deforum, which simplifies video generation with 3D motion for users of all levels.
If you are interested in exploring Stable Diffusion Web UI and its extensions, please refer to the provided reference for more information.
